En el desarrollo de bases de datos, la optimización de consultas es una tarea fundamental para garantizar un buen rendimiento del sistema. En este artículo, exploraremos algunas estrategias prácticas para optimizar consultas en SQL Server.
Cuando se trabaja con bases de datos SQL Server, es común encontrarse con consultas que no están optimizadas, lo que puede resultar en un rendimiento deficiente del sistema. La optimización de consultas implica identificar y resolver cuellos de botella en el rendimiento de las consultas SQL, lo que a su vez mejora la eficiencia y la velocidad de ejecución.
El primer paso en el proceso de optimización de consultas es identificar aquellas consultas que están afectando el rendimiento del sistema. Esto se puede lograr mediante el monitoreo del rendimiento del servidor SQL Server y la identificación de consultas que consumen una cantidad desproporcionada de recursos. Para esto se pueden usar muchas herramientas, en el pasado compartí algunos ejemplos de consultas para monitorear procedimientos almacenados que en realidad funcionan practicamente para cualquier tipo de codigo. Cuando busco consultas que estan dandome problemas habitualmente uso el sp_who2 o bien el sp_whoisactive de Adam Machinic, que a pesar de tener rato de no recibir actualizaciones aún es muy útil.
Una vez identificadas las consultas lentas, es importante analizar los planes de ejecución para entender cómo se están ejecutando esas consultas. El plan de ejecución es una representación visual del proceso que SQL Server sigue para ejecutar una consulta, y puede proporcionar información valiosa sobre posibles cuellos de botella y áreas de mejora.

Los índices son una herramienta fundamental para optimizar consultas en SQL Server. Al crear y mantener índices adecuados, es posible mejorar significativamente el rendimiento de las consultas al permitir un acceso más rápido a los datos.

Una herramienta muy util es el utilizar la visualización de las estadísticas de ejecución con encendiendo el set statistics io, time on;
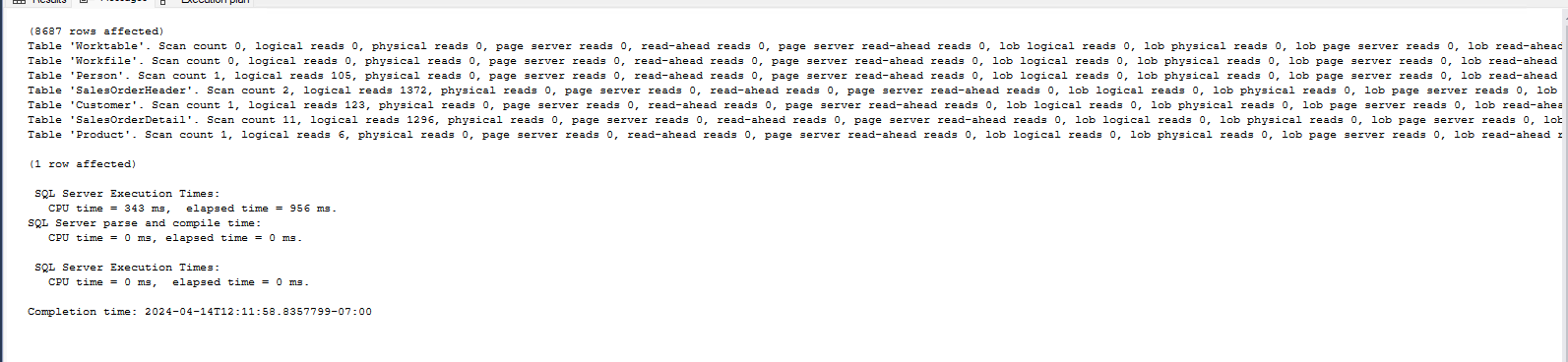
Acá podemos ver cuáles son las tablas que estamos leyendo mas, que tipo de lectura estamos haciendo.
El diseño del esquema de la base de datos también juega un papel crucial en la optimización de consultas. Al diseñar tablas y relaciones de manera eficiente, es posible minimizar el tiempo de búsqueda y recuperación de datos, lo que contribuye a un mejor rendimiento del sistema en su conjunto.
La optimización de consultas en SQL Server es un proceso continuo que requiere un enfoque proactivo y constante. Al implementar estrategias como la identificación de consultas lentas, el análisis de planes de ejecución y el uso eficiente de índices, es posible mejorar significativamente el rendimiento del sistema y proporcionar una experiencia más rápida y eficiente a los usuarios finales.